Streamlitで機械学習のデモアプリ作成

Streamlit を利用して機械学習を用いたデモアプリを作成してみました。
データの分析、可視化からアップロードされたデータの予測まで一連の工程をウェブアプリとして実装しています。
Streamlit を用いることでウェブアプリに詳しくない自分でもとても簡単に機械学習アプリを作ることができました。
この記事では Streamlit を用いたデータ分析アプリの構築方法をコードとともに説明していきます。
コードの全体は github リポジトリ にアップしてあります。
必要に応じて参照してください。
Streamlitとは
Streamlit とはウェブアプリを作成するためのPythonウェブフレームワークの一つです。
データ分析者が簡単に分析結果をウェブアプリとして公開できるように設計されています。
データ分析業界の外の方には意外かもしれませんが、データサイエンティストは分析のアルゴリズムや実務に詳しい一方でアプリの作成方法やインフラ周りには疎いことがあります。
(少なくとも私はそうです。)
そんなデータサイエンティストでも簡単に分析結果をウェブアプリとして構築、公開できるようにしたのが Streamlit の最大の特徴です。
Python のウェブフレームワークといえば Flask や Django あたりが有名です。
Streamlit はこれらに比べ、機能や自由度はそれほどありません。
しかし個人的にはその分圧倒的に手軽に使えるという印象を持ちました。
実際、Streamlitの使用例はネットで調べるとわんさか出てきます。
類似のフレームワークとしては Dash が挙げられます。
Dashはリッチなダッシュボードを作成することが可能でStreamlitよりかなり多機能です。
一方使いこなすにはそれなりに学習コストがかかります。
Streamlitは機能が絞られている分、学習コストが低いのが Dash との違いとなるでしょう。
今回はStreamlitのお試しとして、機械学習を用いた簡単なウェブアプリを作成してみます。
今回作成するアプリ
今回作成するのは、データ分析から機械学習によるデータの予測までの一連の流れをウェブアプリとしてまとめたものとします。
具体的には、
- 学習用データを読み込み、表示する。
- データをグラフとして可視化する。
- 決定木でデータを学習する。
- 学習した決定木をグラフとして可視化する。
- 予測対象となるデータをアップロードする。
- アップロードされた予測対象データの予測値を表示する。
という流れを実装していきます。
本来のユースケースとしては、学習は別環境で行っておき学習済みモデルと予測対象データを用いて予測結果を表示するなり返すなりするのが王道ではありますが、ここでは簡易に学習も流れの中で行ってしまいます。
(今回、予測対象ファイルのアップロードは手作業で行いますが、ここを自動化できれば学習用データを定期的にアップロードして学習するなどもできるかもしれません。)
使用するデータ
今回は学習と予測用のデータとして言わずと知れた Iris データセット を用います。
Iris データセットはアヤメの花の花弁の長さと幅、ガクの長さと幅を元にアヤメの花の種類を分類するタスクとして用いられます。
今回は学習に Iris データセットの全データを用い、
予測用のファイルとして Iris データセットからランダムに 10 行抽出したデータを用います。
学習したデータを再度予測に用いるので面白みはないのですが…面倒なので 本筋を分かりやすくする簡略化として今回はこのセットアップで行きます。
Streamlitによるウェブアプリの構築
ここからコードベースで Streamlit で作るウェブアプリについて説明していきます。
今回は特にファイルやディレクトリを分割することなく、1 ファイル (streamlit_demo.py) で作成していきます。
環境構築
Docker コンテナとして開発環境を構築していきます。
特筆すべきことも無いので、いきなり Dockerfile を示します。
FROM python:3.9.6-buster
# パッケージインストールとlocaleの設定
RUN apt-get update && \
apt-get -y upgrade && \
apt-get -y install sudo vim locales graphviz && \
localedef -f UTF-8 -i ja_JP ja_JP.UTF_8
ENV LANG ja_JP.UTF-8
ENV LANGUAGE ja_JP:ja
ENV LC_ALL ja_JP.UTF-8
ENV TZ JST-9
# キャッシュクリア
RUN apt-get clean
# pythonライブラリインストール
RUN python -m pip install --upgrade pip
RUN python -m pip install --upgrade setuptools
COPY requirements.txt /tmp/
RUN python -m pip install -r /tmp/requirements.txt
# ユーザーを作成。ビルド時に渡す。
ARG u_id
ARG u_name
ARG u_passwd
ENV DOCKER_UID=${u_id}
ENV DOCKER_USER=${u_name}
ENV DOCKER_PASSWORD=${u_passwd}
## 作成したユーザをsudoグループに加える
RUN useradd -m --uid ${DOCKER_UID} --groups sudo ${DOCKER_USER} \
&& echo ${DOCKER_USER}:${DOCKER_PASSWORD} | chpasswd
## 作成したユーザーに切り替える
USER ${DOCKER_USER}
# ワーキングディレクトリ変更
WORKDIR /home/dogscox
注意点としてはコンテナ内外でユーザ ID 、グループ ID を一致させている点でしょうか。
こうすることでコンテナ内でファイルを編集したらコンテナ外で触れなくなった、ということがなくなります。
(逆に言えば本番環境でソースをいじるということはほとんど無いと思うので、開発環境向けの設定ではあります。)
UID 等をコンテナのビルド時に渡す必要があるので、ビルドコマンドは
$docker build ./ --build-arg u_id=$UID --build-arg u_name=$USER --build-arg u_passwd="xxxx"
のように環境変数を渡す必要があります。
requirements.txt は必要な Python パッケージを羅列しているだけです。
numpy
scipy
pandas
scikit-learn
streamlit
graphviz
matplotlib
plotly
seaborn
決定木の可視化用として Graphviz をインストールしています。
データの準備
それでは、 streamlit_demo.py をガリガリ書いていきましょう。
まずは必要なライブラリのインポートとデータの準備です。
Iris データセットは scikit-learn のサンプルデータセット に含まれるので、そちらからロードします。
""" streamlit_demo
streamlitでIrisデータセットの分析結果を Web アプリ化するモジュール
"""
import numpy as np
import pandas as pd
import streamlit as st
import matplotlib.pyplot as plt
import seaborn as sns
import graphviz
import plotly.graph_objects as go
# irisデータセットでテストする
from sklearn.datasets import load_iris
# 決定木で分類してみる
from sklearn import tree
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
sns.set()
def make_iris_df():
""" Irisデータフレーム作成関数
Irisデータセットをデータフレームとして返す関数
Args:
Returns:
df(pd.DataFrame): Irisデータセットのデータフレーム
"""
dataset = load_iris()
df = pd.DataFrame(dataset.data)
# 変数名を列名に代入
df.columns = dataset.feature_names
# 目的変数を設定
df["species"] = dataset.target
return df
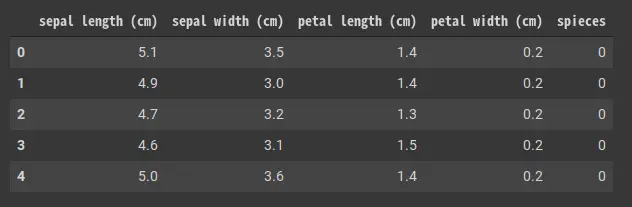
make_iris_df() 関数で Iris データセットを pandas.DataFrame に変換しています。
データは以下のようになります。
データの表示
まずはデータを画面に表示してみます。
Streamlit は pandas.DataFrame を streamlit.dataframe() 関数で簡単に画面に表示させることができます。
また、この際に表示する行数をユーザが選べるようにしてみます。
こちらも streamlit.number_input() 関数で簡単に実装できます。
def st_display_df(df: pd.DataFrame):
""" データフレーム表示関数
streamlitでデータフレームを表示する関数
Args:
df(pd.DataFrame): stで表示するデータフレーム
Returns:
"""
# 表示する行数を選択
row_size = st.number_input(
"表示する行数を選択してください(下スクロールで追加行が表示されます)。",
min_value=10,
max_value=50,
value=10,
step=10
)
# データフレームを表示
st.dataframe(df.head(row_size))
メイン部分で以下のように上記の関数を呼び出し、スクリプトを実行します。
def st_display_df...
if __name__ == "__main__":
df = make_iris_df()
# stのタイトル表示
st.title("Iris データセットで Streamlit をお試し")
# データフレーム表示
st.markdown(r"## Iris データの詳細")
st_display_df(df)
st.text("")
メイン部分ではウェブアプリの上部に記述するタイトルや適宜説明を加えています。
markdown 記法で書けるのは嬉しいですね。他にも Latex 記法も使えたりするようです。
スクリプトの実行は Dockerコンテナ実行時にフォワーディングしたポートを指定します。
$streamlit run streamlit_demo.py --server.port=8888
このあたりの設定は config ファイルや環境変数で設定することも可能です。
詳細は公式ページをご覧ください。
さて、上記のようにウェブアプリを実行してブラウザで localhost:8888 にアクセスすると次のように表示されるはずです。
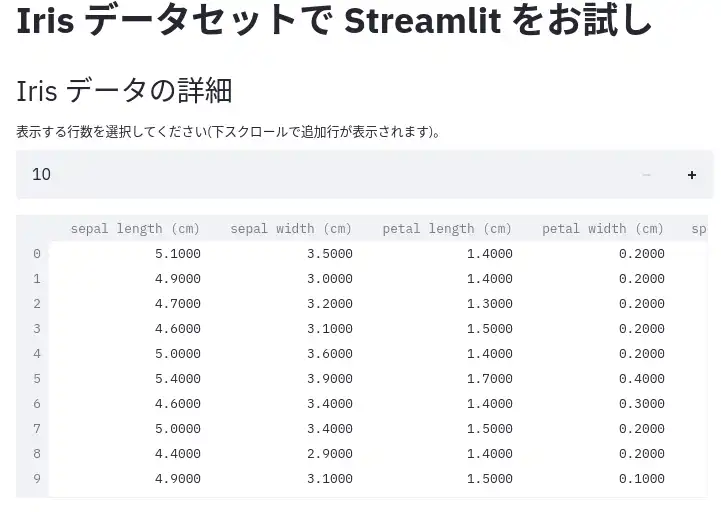
上部の + ボタンで表示行数を設定できます。
図のように、自動でスクロール設定などがされます。
このあたりは好き嫌いあるかも知れませんが、個人的には楽で良いなと思いました。
matplotlib グラフ表示
それでは分析の第一歩(そして最後のステップ)としてデータを可視化してみましょう。
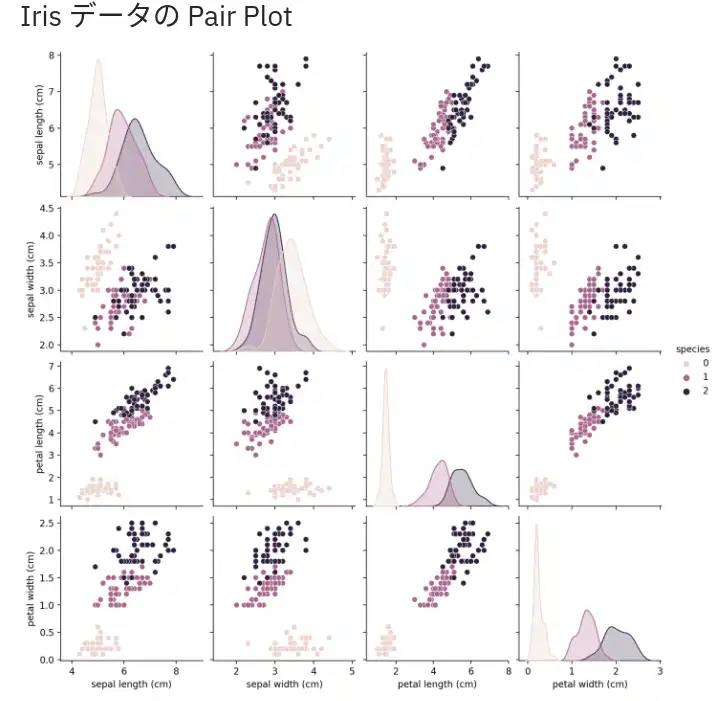
可視化には seaborn.pairplot を用います。
pairplot は各変数の分布と相関が一覧できて便利です。
変数が多くなるとプロットがとても重くなるので必要に応じて事前の特徴量選択が必要ですが。
さて、プロットを生成して画面上に出力する関数は以下です。
def st_display_pairplot(df: pd.DataFrame):
""" ペアプロットをstに表示する関数
streamlitでsns.pairplotを表示する関数
Args:
df(pd.DataFrame): pairplotを作成するデータ
Returns:
"""
# ペアプロットを作成
fig = plt.figure()
fig = sns.pairplot(df, hue="species")
# stで表示
st.pyplot(fig)
こちらも streamlit.pyplot() 関数で簡単に出力できましたね。
ウェブアプリ上では以下のように出力されます。
(上部の説明文はメイン部分で markdown で出力しています。)
plotlyグラフの表示
Iris データの可視化としては pairplot で十分なのですが、
Streamlit の便利機能の紹介として Plotly との連携の例を取り上げます。
Plotly は拡大縮小や範囲の絞り込みなどをグラフ上で行える動的なグラフを作成するための Python ライブラリです。
Streamlit 上で Plotly によるグラフを出力することでマウスでグリグリ動かせるグラフを出力できます。
def st_display_plotly(df: pd.DataFrame):
"""plotlyグラフをstに表示する関数
streamlitでplotlyグラフを表示する関数
Args:
df(pd.DataFrame): plotlyグラフを作成するデータ
Returns:
"""
# plotlyグラフを適当に作成
fig = go.Figure(data=[
go.Scatter(
x=df.loc[df["species"]==0, "petal length (cm)"],
y=df.loc[df["species"]==0, "petal width (cm)"],
name="setosa",
mode="markers"),
go.Scatter(
x=df.loc[df["species"]==1, "petal length (cm)"],
y=df.loc[df["species"]==1, "petal width (cm)"],
name="versicolor",
mode="markers"),
go.Scatter(
x=df.loc[df["species"]==2, "petal length (cm)"],
y=df.loc[df["species"]==2, "petal width (cm)"],
name="virginica",
mode="markers"),
])
# stに表示
st.plotly_chart(fig, user_container_width=True)
こちらも streamlit.plotly_chart() 関数で一発です。以下のように表示されます。
(Plotly についての説明は割愛します。)
ブラウザ上で拡大縮小ができるグラフを作れます。
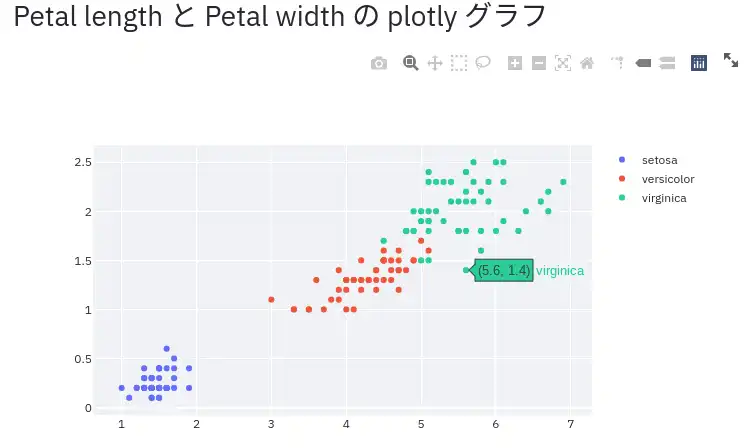
Streamlit は Plotly 以外にも Bokeh や Altair など有名な Python のグラフ描画パッケージと連携可能です。
決定木の学習と可視化
それでは機械学習へと進みましょう。
今回は決定木で分類を行ってみます。
また、学習後には学習の結果得られた決定木もウェブアプリ上に可視化してみます。
def ml_dtree(
X: pd.DataFrame,
y: pd.Series) -> list:
""" 決定木で学習、予測を行う関数
Irisデータセット全体で学習し、学習データの予測値を返す関数
Args:
X(pd.DataFrame): 説明変数郡
y(pd.Series): 目的変数
Returns:
List: [モデル, 学習データを予測した予測値, accuracy]のリスト
"""
# 学習
clf = DecisionTreeClassifier(max_depth=5)
clf.fit(X, y)
# 予測
pred = clf.predict(X)
# accuracyで精度評価
score = accuracy_score(y, pred)
return [clf, pred, score]
def st_display_dtree(clf):
"""決定木可視化関数
streamlitでDtreeVizによる決定木を可視化する関数
Args:
clf(sklearn.DecisionTreeClassifier): 学習済みモデル
Return:
"""
# graphvizで決定木を可視化
dot = tree.export_graphviz(clf, out_file=None)
# stで表示する
st.graphviz_chart(dot)
ml_dree() 関数で学習したモデルを st_display_dtree() 関数でウェブアプリ上に表示しています。
これは Streamlit の streamlit.graphviz_chart() という Graphviz との連携機能で実現されます。
以下のように表示されます。
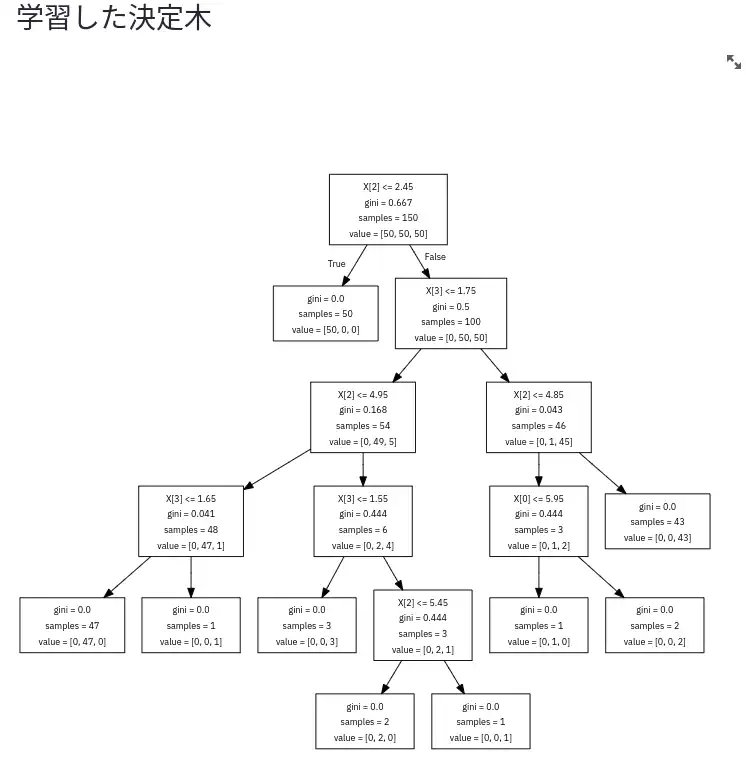
最終的に Gini 不純度が 0 になっていますね。完全に分類できたようです。
今回はこの程度ですが、例えばハイパーパラメータの max_depth を変えたときに決定木がどう変化するかなど、
色々アプリ上で動かせるようにすると面白いかも知れません。
予測用データアップロード
さて、学習済みモデルが得られたので、新たなデータ(新しくはないのですが)で予測をしてみましょう。
まずは予測に用いるデータをアップロードする機能を実装します。
事前に学習データから 10 件ランダム抽出しておいたファイルを用意しておきます。
ファイルアップロード機能を実装した関数は以下です。
def st_file_uploader() -> pd.DataFrame:
""" ファイルアップロードを受け付ける関数
streamlitでファイルアップロードを受け付ける関数
Args:
Returns:
pd.DataFrame: 予測用のデータ
"""
uploaded_file = st.file_uploader(
"予測対象となる CSV ファイルをアップロードしてください。",
type="csv",
accept_multiple_files=False
)
if uploaded_file:
pred_df = pd.read_csv(uploaded_file)
return pred_df
else:
return pd.DataFrame()
streamlit.file_uploader() 関数を使うだけで実装できました。
このあたり、本当は例外処理やデータのバリデーションを行ったほうが良いですね。
これでウェブアプリ上にドラッグ & ドロップでファイルをアップロードできる画面が作られます。
予測
では、アップロードされたデータに対して予測を行いましょう。
def ml_pred(clf, X: pd.DataFrame) -> np.array:
""" 予測用関数
与えられたデータに対して予測値を返す関数
Args:
clf(sklearn.tree.DecisionTreeClassifier): 学習済みモデル
X(pd.DataFrame): 予測対象データ
Returns:
np.array: 予測結果
"""
pred = clf.predict(X)
return pred
予測自体は学習済みモデルを使って予測させるだけです。
一点注意として、この関数を実行するのは 予測用のデータが存在するときのみ であることに留意しましょう。
予測用ファイルが無いのにこの関数が実行されると当然エラーになります。
そのため、メイン部分は以下のように予測用のデータがあるときに予測を行うように実装します。
def ml_pred...
if __name__ == "__main__":
...
# 予測対象ファイルの受付
st.markdown(r"## 予測用ファイルをアップロードしてください。")
pred_df = st_file_uploader()
# 予測対象の予測値を算出
if len(pred_df):
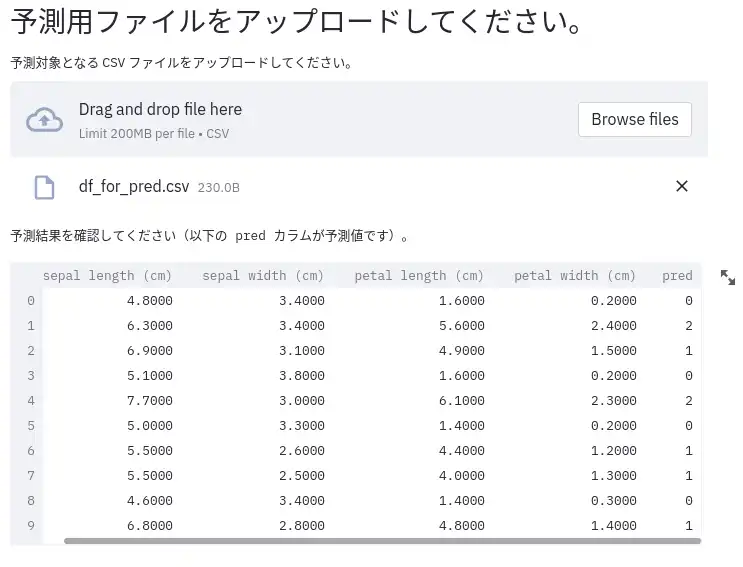
st.text("予測結果を確認してください(以下の pred カラムが予測値です)。")
pred_df["pred"] = ml_pred(clf, pred_df)
st.dataframe(pred_df)
これでアップロードされたデータに対して予測が行われます。
これでデータ分析から機械学習による予測までの一連の流れをウェブアプリとして実装できました。streamlit_demo.py の全体像は githubリポジトリ を参照してください。
最後に
おめでとうございます!!
これで機械学習アプリが作成できました!!
といってもウェブアプリとしてはほぼStreamlitの関数を 1 行呼び出すだけでしたね。
非常に手軽に使えることを感じていただけたのではないでしょうか?
Streamlit 自体は Python スクリプトをベースとしたウェブアプリとして動作しているので、
例えばデータベースからストリームもしくはバッチで取得したデータに対して予測を回してグラフ化し、
ダッシュボード的に使ったりもできそうですね。
小さなMLOpsが実現できそうです。
さて、今回はユーザが動かせる部分は表示の行数やグラフのみと限定的でした。
しかし、今回のデモで示したようにStreamlitではユーザがインタラクティブに操作できる機能も提供しています。
例えば、アプリ上で条件を変えつつシミュレーションした結果を確認するなどもできそうですね。
時間があればそのような用途にStreamlitを使ってみた記事も今後書きたいと思います。